Module 2.3: Surfaces - Accuracy in DEMs
The purpose of this week's lab was to determine the vertical accuracy of DEMs, including determining bias. I was given a high resolution DEM for a section of North Carolina created from LIDAR data and a table of field data of elevation at the ground surface collected using high accuracy survey methods. The table contained 5 land cover types (a-e). The table had coordinates for each point which were converted to a point shapefile using the XY Table to Point tool. The points within the DEM were selected and saved as a separate shapefile for the analysis.
To get the values of the raster beneath the points, I used the Extract Multi Values to Points. This tools grabs the elevation value of the pixel in the DEM directly beneath each sample point and then adds a new field to the point shapefile with that value. Because these values were in feet, I added a new field to the attribute table and converted the feet to meters. I then calculated accuracy for each land cover type as well as the entire data set. The calculations included the root mean square (RMSE), accuracy at the 68th percentile, accuracy at the 95th percentile, and Bias (or mean error). The summary of the results of these calculations is below:
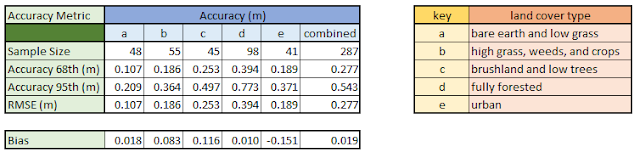
RMSE is the most common metric used to evaluate accuracy. The lower the RMSE, the more accurate the result. RMSE was calculated using the following formula from Fisher and Tate (2006)*:
 I calculated bias using the mean error (ME) using the following equation from Fisher and Tate (2006)*:
I calculated bias using the mean error (ME) using the following equation from Fisher and Tate (2006)*:
 Using this calculation, bias or ME can either be positive or negative. This represents the overall under- or overestimation of the elevations in the DEM. Positive values indicate where values were overestimated whereas negative values indicate areas where values were underestimated. Both types of bias exist in this data set and vary by land cover type.
Using this calculation, bias or ME can either be positive or negative. This represents the overall under- or overestimation of the elevations in the DEM. Positive values indicate where values were overestimated whereas negative values indicate areas where values were underestimated. Both types of bias exist in this data set and vary by land cover type.
*Fisher, P.F., and N.J. Tate. 2006. Causes and consequences of error in digital elevation models. Progress in Physical Geography, 30(4), 467-489.
To get the values of the raster beneath the points, I used the Extract Multi Values to Points. This tools grabs the elevation value of the pixel in the DEM directly beneath each sample point and then adds a new field to the point shapefile with that value. Because these values were in feet, I added a new field to the attribute table and converted the feet to meters. I then calculated accuracy for each land cover type as well as the entire data set. The calculations included the root mean square (RMSE), accuracy at the 68th percentile, accuracy at the 95th percentile, and Bias (or mean error). The summary of the results of these calculations is below:

RMSE is the most common metric used to evaluate accuracy. The lower the RMSE, the more accurate the result. RMSE was calculated using the following formula from Fisher and Tate (2006)*:
*Fisher, P.F., and N.J. Tate. 2006. Causes and consequences of error in digital elevation models. Progress in Physical Geography, 30(4), 467-489.


Comments
Post a Comment